Using Pandas with PyMPX
Importing the pympx module will add extra functionality to the pandas module.
The extra functions behave in a similar way to pd.read_csv() and pd.DataFrame.to_csv()
Reading from Empower into a pandas DataFrame
For example pd.read_empower() returns a pandas DataFrame in the same way that pd.read_csv() does:
import pandas as pd
from pympx import pympx as mpx
site = mpx.Site(r"C:\Empower Sites\Sunrise Brands Limited\Sunrise Brands Limited.eks")
df = pd.read_empower(site.dimensions[0])
df.head()
| ID | Short Name | Long Name | Description | Group Only | Calculation Status | Calculation | Colour | Measure Element | NewField | ... | Geography3 | Geography4 | Geography5 | Geography6 | Geography7 | Geography8 | Geography9 | Geog_L1 | Geog_L2 | Geog_L3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | ALL | ALL | None | None | Real | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 1 | 2 | TMarkets | Global Markets | None | None | Real | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 2 | 3 | NA | North America | North America | None | Real | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 3 | 4 | Europe | Europe | Europe | None | Real | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
| 4 | 5 | UK | UK | United Kingdom | None | Real | None | None | None | None | ... | None | None | None | None | None | None | None | None | None | None |
5 rows × 30 columns
The returned dataframe contains the standard Empower fields, and the Empower custom fields. In the example above NewField is an Empower custom attribute. The column ID contains the Empower physid.
Tip
Typing the dot (.) symbol and then the [TAB] key will bring up the pandas autocomplete. If you type part of a method name you can see the matching methods in the dropdown list.
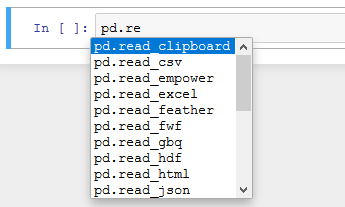
pd.read_empower() appears in the dropdown along with the standard pandas read functions.
Creating elements from csv, via a pandas DataFrame
Elements can be created from csv very easily, via a pandas DataFrame.
The one difficulty is to know that the DataFrame’s columns need renaming to the standard dimension field names
Short Name
Long Name
Description
Group Only
Calculation Status
Calculation
Colour
Measure Element
…and custom field longnames
Example: Creating Elements from csv¶
This notebook shows an example of reading in a csv file and creating elements fro mit, via pandas
import pandas as pd
from pympx import pympx as mpx
We are going to create the elements in the sunrise site - so log on
sunrise = mpx.Site(r"C:\Empower Sites\Sunrise Brands Limited\Sunrise Brands Limited.eks")
The elements will be created in the spare Unit 7 dimension for this example
unit7 = sunrise.dimensions[6]
unit7.longname
'Unit 7'
Next we need to read the elements in from the csv file - we can do this using pandas
df = pd.read_csv(r"new_elements.csv")
The example data is a list of pairs of Common English and Latin Names of some plants
df
| Common Name | Latin Name | |
|---|---|---|
| 0 | Bamboo | Bambuseae |
| 1 | Banana | Musa x paradisiaca |
| 2 | Baobab | Adansonia |
| 3 | Bay laurel | Laurus nobilis |
| 4 | California bay | Umbellularia californica |
| 5 | Bean | Fabaceae |
| 6 | Bearberry | Ilex decidua |
| 7 | Bear corn | Veratrum viride |
| 8 | Beech | Fagus |
| 9 | Blue bindweed | Solanum dulcamara |
| 10 | Bird's nest plant | Daucus carota |
| 11 | Bird of paradise | Strelitzia reginae |
To load the data into empower, we will need to change the column names, to the standard empower field names
df.rename(columns={'Common Name':'Long Name','Latin Name':'Description'},inplace=True)
df
| Long Name | Description | |
|---|---|---|
| 0 | Bamboo | Bambuseae |
| 1 | Banana | Musa x paradisiaca |
| 2 | Baobab | Adansonia |
| 3 | Bay laurel | Laurus nobilis |
| 4 | California bay | Umbellularia californica |
| 5 | Bean | Fabaceae |
| 6 | Bearberry | Ilex decidua |
| 7 | Bear corn | Veratrum viride |
| 8 | Beech | Fagus |
| 9 | Blue bindweed | Solanum dulcamara |
| 10 | Bird's nest plant | Daucus carota |
| 11 | Bird of paradise | Strelitzia reginae |
Because a short name has not been set, the elements will be synchronised immediately, and shortnames will be created for the elements
We could have chosen different keys to merge, using fields or Short Name as keys if we had wanted to.
elements.merge always returns a merged Element, list or DataFrame, depending on what was passed into it. The returned dataframe holds the canonical values of the elements in Empower.
unit7.elements.merge(df,keys=['Long Name'])
| ID | Short Name | Long Name | Description | Group Only | Calculation Status | Calculation | Colour | Measure Element | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | Total | Total | None | None | Real | None | None | None |
| 1 | 2 | Bamboo0 | Bamboo | Bambuseae | None | None | None | None | None |
| 2 | 3 | Banana1 | Banana | Musa x paradisiaca | None | None | None | None | None |
| 3 | 4 | Baobab2 | Baobab | Adansonia | None | None | None | None | None |
| 4 | 5 | Baylaurel3 | Bay laurel | Laurus nobilis | None | None | None | None | None |
| 5 | 6 | Californiabay4 | California bay | Umbellularia californica | None | None | None | None | None |
| 6 | 7 | Bean5 | Bean | Fabaceae | None | None | None | None | None |
| 7 | 8 | Bearberry6 | Bearberry | Ilex decidua | None | None | None | None | None |
| 8 | 9 | Bearcorn7 | Bear corn | Veratrum viride | None | None | None | None | None |
| 9 | 10 | Beech8 | Beech | Fagus | None | None | None | None | None |
| 10 | 11 | Bluebindweed9 | Blue bindweed | Solanum dulcamara | None | None | None | None | None |
| 11 | 12 | Birdsnestplant10 | Bird's nest plant | Daucus carota | None | None | None | None | None |
| 12 | 13 | Birdofparadise11 | Bird of paradise | Strelitzia reginae | None | None | None | None | None |
In this example we do not need to synchronise, because it was done automatically. We have synchronised as good practice below anyway
unit7.elements.synchronise()
unit7.elements
{'Total':<Element object, shortname Total, longname Total at 0x1b045acdb40>
'Bamboo0':<Element object, shortname Bamboo0, longname Bamboo at 0x1b045accf40>
'Banana1':<Element object, shortname Banana1, longname Banana at 0x1b045acc880>
'Baobab2':<Element object, shortname Baobab2, longname Baobab at 0x1b045acde40>
'Baylaurel3':<Element object, shortname Baylaurel3, longname Bay laurel at 0x1b045accd00>
'Californiabay4':<Element object, shortname Californiabay4, longname California bay at 0x1b045ace6e0>
'Bean5':<Element object, shortname Bean5, longname Bean at 0x1b045ace620>
'Bearberry6':<Element object, shortname Bearberry6, longname Bearberry at 0x1b045ace560>
'Bearcorn7':<Element object, shortname Bearcorn7, longname Bear corn at 0x1b045ace410>
'Beech8':<Element object, shortname Beech8, longname Beech at 0x1b045ace350>
'Bluebindweed9':<Element object, shortname Bluebindweed9, longname Blue bindweed at 0x1b045ace0e0>
'Birdsnestplant10':<Element object, shortname Birdsnestplant10, longname Bird's nest plant at 0x1b045acd9f0>
'Birdofparadise11':<Element object, shortname Birdofparadise11, longname Bird of paradise at 0x1b045ace7d0>} from <_ElementsGetter object at 0x1b045a777c0>
Creating a hierarchy from a flat list in a pandas DataFrame
Hierarchy structure can be loaded from pandas DataFrames.
Using the StructureElement.embellish() method¶
In this example notebook, a StructureElement tree is created from pandas DataFrame.
At each stage of tree creation the StructureElement.embellish() method is called. The tree grows layer by layer, using child-parent relationships supplied in the DataFrame.
The first stage is to import the modules we need. empower_utils version 0.6.2 or greater will suffice.
from pympx import pympx as mpx
import pandas as pd
Here we have a simple DataFrame with three records. There is an implied hierarchy within the data, which we will use stage by stage to build the Empower hierarchy
df = pd.DataFrame([{ 'Dept' :'Lifestyle'
,'Sector':'Caravanning'
,'Title' :'Caravan Enthusiast'
}
,{ 'Dept' :'Lifestyle'
,'Sector':'Caravanning'
,'Title' :'Caravanning'
}
,{ 'Dept' :'Lifestyle'
,'Sector':'Camping'
,'Title' :'Happy Campers'
}
])
df
| Dept | Sector | Title | |
|---|---|---|---|
| 0 | Lifestyle | Caravanning | Caravan Enthusiast |
| 1 | Lifestyle | Caravanning | Caravanning |
| 2 | Lifestyle | Camping | Happy Campers |
Log on to the Sunrise site. Because we use dimension 0 a lot in this example, we create a variable refering to it, dim0.
sunrise = mpx.Site(r"C:\Empower Sites\Sunrise Brands Limited\Sunrise Brands Limited.eks")
dim0 = sunrise.dimensions[0]
Create the fields we will need to track the dimension Elements being created for this hierarchy.
Synchronise the site definition with Empower, so that it knows about the new fields on dimension 0
dim0.fields['Type'] = mpx.FieldDefinition(longname='Type', shortname='Type' )
dim0.fields['Department'] = mpx.FieldDefinition(longname='Department',shortname='Department')
dim0.fields['Sector'] = mpx.FieldDefinition(longname='Sector', shortname='Sector' )
dim0.fields['Mag_Title'] = mpx.FieldDefinition(longname='Mag_Title', shortname='Mag_Title' )
sunrise.definition.synchronise()
Create some of the elements we need for the hierarchy.
The embellish method will automatically create new elements if the required elements do not already exist.
Note that the elements are of different types, to help differentiate between elements being created at different levels of the hierarchy.
ALL = mpx.Element(dimension = dim0, shortname = 'ALL', longname = 'ALL', fields = {'Type':'ALL', 'Department':None, 'Sector':None, 'Mag_Title':None})
LIF = mpx.Element(dimension = dim0, shortname = 'LIF', longname = 'Lifestyle', fields = {'Type':'Dep', 'Department':'Lifestyle', 'Sector':None, 'Mag_Title':None})
CAR = mpx.Element(dimension = dim0, shortname = 'CAR', longname = 'Caravanning', fields = {'Type':'Sector', 'Department':'Lifestyle', 'Sector':'Caravanning', 'Mag_Title':None})
CAE = mpx.Element(dimension = dim0, shortname = 'CAE', longname = 'Caravan Enthusiast', fields = {'Type':'Magazine', 'Department':'Lifestyle', 'Sector':'Caravanning', 'Mag_Title':'Caravan Enthusiast'})
CVN = mpx.Element(dimension = dim0, shortname = 'CVN', longname = 'Caravanning', fields = {'Type':'Magazine', 'Department':'Lifestyle', 'Sector':'Caravanning', 'Mag_Title':'Caravanning'})
Merge element definitions with those already in the dimension.
Get the merged elements so that we can ensure we are using the mastered versions of the elements, and ensure that they exist in the site by synchronising.
ALL,LIF,CAR,CAE,CVN = dim0.elements.merge([ALL,LIF,CAR,CAE,CVN])
dim0.elements.synchronise()
Create the top level structure element.
We will be adding children to this StructureElement
all_se = mpx.StructureElement(element = ALL)
The hierarchy is very basic at this point - just a single top-level node.
print(all_se)
ALL (0) ALL
We embellish the hierarchy using the mappings in the DataFrame.
Where the parameters of the .embellish() method are named "...mapping" they refer to a column in the DataFrame.
Where the parameters of the .embellish() method are named "...fields" they refer to fields in the Dimension.
- element_type_field is the field in the Dimension that distinguishes the types of element
- child_type is a constant that will be stored in the "Type" field for any elements created, and will be used to distinguish elements that belong at this level of the hierarchy from elements created for other levels of this hierarchy.
- child_element_id_fields are the fields in the Dimension element that distinguish this element from others of the same type
- child_element_id_mappings are the columns in the DataFrame that relate to the child_element_id_fields
- child_longname_mapping is the column in the DataFrame which contains the longname which we will create new elements with. Existing elements (which have a "Type" field of "Dep" and a "Department" field matching the "Dept" column in the example below) will keep their longnames.
all_se.embellish( mappings = df
, element_type_field = 'Type'
, child_type = 'Dep'
, child_element_id_fields = ['Department']
, child_element_id_mappings = ['Dept']
, child_longname_mapping = 'Dept'
)
The unique values in df['Dept'] are used to embellish the "ALL" node.
Since there are no parent criteria in the call to the .embellish() method, all children are added to the "ALL" node.
A new node using the "LIF" element is created under "ALL":
print(all_se)
ALL (0) ALL +-LIF (1) Lifestyle
In the next round of hierarchy embellishment, values in the the 'Sector' column get mapped to children under the 'LIF' node.
The 'child...' parameters in the previous call to embellish have become the 'parent...' parameters in this call, because we want to embellish only the nodes we just added.
The 'child...' parameters in this call to embellish refer to the 'Sector' column in the DataFrame and 'Sector' field in the dimension.
all_se.embellish( mappings = df
, element_type_field = 'Type'
, parent_type = 'Dep'
, parent_element_id_fields = ['Department']
, parent_element_id_mappings = ['Dept']
, child_type = 'Sector'
, child_element_id_fields = ['Sector']
, child_element_id_mappings = ['Sector']
, child_longname_mapping = 'Sector'
)
Note that a new element has automatically been created: 'Camping___'.
This element was created becasue there was no existng element in the dimension with fields 'Type':'Sector' and 'Sector':'Camping'
print(all_se)
ALL (0) ALL +-LIF (1) Lifestyle +-CAR (2) Caravanning +-Camping___ (3) Camping
Finally we add the magazine titles on. Once again the 'child...' parameters in the previous call have become the 'parent...' parameters in this call to the .embellish() method.
all_se.embellish( mappings = df
, element_type_field = 'Type'
, parent_type = 'Sector'
, parent_element_id_fields = ['Sector']
, parent_element_id_mappings = ['Sector']
, child_type = 'Magazine'
, child_element_id_fields = ['Mag_Title']
, child_element_id_mappings = ['Title']
, child_longname_mapping = 'Title'
)
print(all_se)
ALL (0) ALL
+-LIF (1) Lifestyle
+-CAR (2) Caravanning
| +-CAE (3) Caravan Enthusiast
| +-CVN (4) Caravanning
+-Camping___ (5) Camping
+-HappyCampe (6) Happy Campers
Note that the elements that have been automatically created have been given the appropriate "Type" field. The "HappyCampe0" element has the "Mag_Title" field set, but not the "Sector", or "Department" fields. Additional code would need to be written to update these fields.
The fields that have been populated are enough to ensure that the new elements are reused during the next run of this notebook code.
dim0.elements['HappyCampe0'].fields
--------------------------------------------------------------------------- KeyError Traceback (most recent call last) Input In [17], in <cell line: 1>() ----> 1 dim0.elements['HappyCampe0'].fields File C:\virtual_envs\pympx_test_env\lib\site-packages\pympx\pympx.py:1812, in _ElementsGetter.__getitem__(self, item) 1809 if not self._elements_read: 1810 self._load_elements(debug=self.dimension.site._debug) -> 1812 return self._elements[item] KeyError: 'HappyCampe0'